Data format
To carry out a systematic review with ASReview on your own dataset, your data file needs to adhere to a certain format. ASReview accepts the following formats:
Tabular file format
Tabular datasets with extensions .csv, .tab, .tsv, or .xlsx
can be used in ASReview LAB. CSV and TAB files are preferably comma,
semicolon, or tab-delimited. The preferred file encoding is UTF-8 or
latin1.
For tabular data files, the software accepts a set of predetermined column names:
Name |
Column names |
Mandatory |
|---|---|---|
Title |
title, primary_title |
yes* |
Abstract |
abstract, abstract note |
yes* |
Keywords |
keywords |
no |
Authors |
authors, author names, first_authors |
no |
DOI |
doi |
no |
URL |
url |
no |
Included |
final_included, label, label_included, included_label, included_final, included, included_flag, include |
no |
* Only a title or an abstract is mandatory.
Title, Abstract Each record (i.e., entry in the dataset) should hold
metadata on a paper. Mandatory metadata are only title or abstract. If
both title and abstract are available, the text is combined and used for
training the model. If the column title is empty, the software will search
for the next column primary_title and the same holds for abstract and
abstract_note.
Keywords, Authors If keywords and/or author (or if the column is
empty: author names or first_authors) are available it can be used for
searching prior knowledge. Note the information is not shown during the
screening phase and is also not used for training the model, but the
information is available via the API.
DOI and URL
If a Digital Object Identifier ( DOI) is available it will be displayed during the
screening phase as a clickable hyperlink to the full text document. Similary, if a URL
is provided, this is also displayed as a clickable link. Note by
using ASReview you do not automatically have access to full-text and if you do
not have access you might want to read this blog post.
Included
A binary variable indicating the existing labeling decisions with 0 =
irrelevant/excluded, or 1 = relevant/included. If no label is present, we
assume the record is not seen by the reviewer. Different column names are allowed,
see the table. The behavior of the labels is different for each mode,
see Fully, partially, and unlabeled data.
RIS file format
RIS file formats (with extensions .ris or .txt) are used by digital
libraries, like IEEE Xplore, Scopus and ScienceDirect. Citation managers
Mendeley, RefWorks, Zotero, and EndNote support the RIS file format as well.
See (wikipedia) for
detailed information about the format.
For parsing RIS file format, ASReview LAB uses a Python RIS files parser and reader (rispy). Successful import/export depends on a proper data set structure. The complete list of accepted fields and default mapping can be found on the rispy GitHub page.
The labels ASReview_relevant, ASReview_irrelevant, and
ASReview_not_seen are stored with the N1 (Notes) tag, and can be
re-imported into ASReview LAB. The behavior of the labels is different for
each mode, see Fully, partially, and unlabeled data.
Tip
The labels ASReview_relevant, ASReview_irrelevant, and
ASReview_not_seen are stored with the N1 (Notes) tag. In citation managers
Zotero and Endnote the labels can be used for making selections; see the
screenshots or watch the instruction video.
Note
When re-importing a partly labeled dataset in the RIS file format, the labels stored in the N1 field are used as prior knowledge. When a completely labeled dataset is re-imported it can be used in the Exploration and Simulation mode.
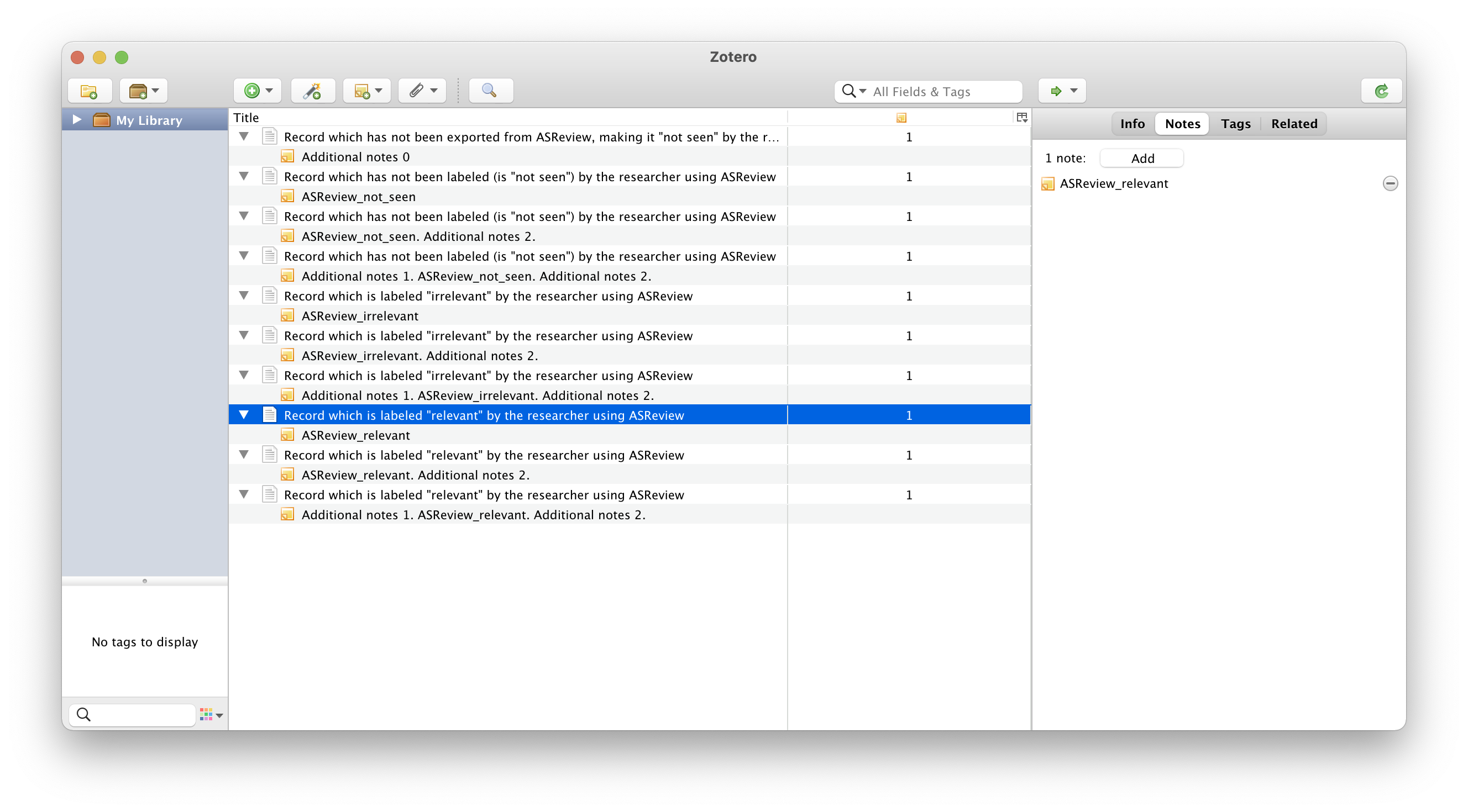
Example record with a labeling decision imported to Zotero
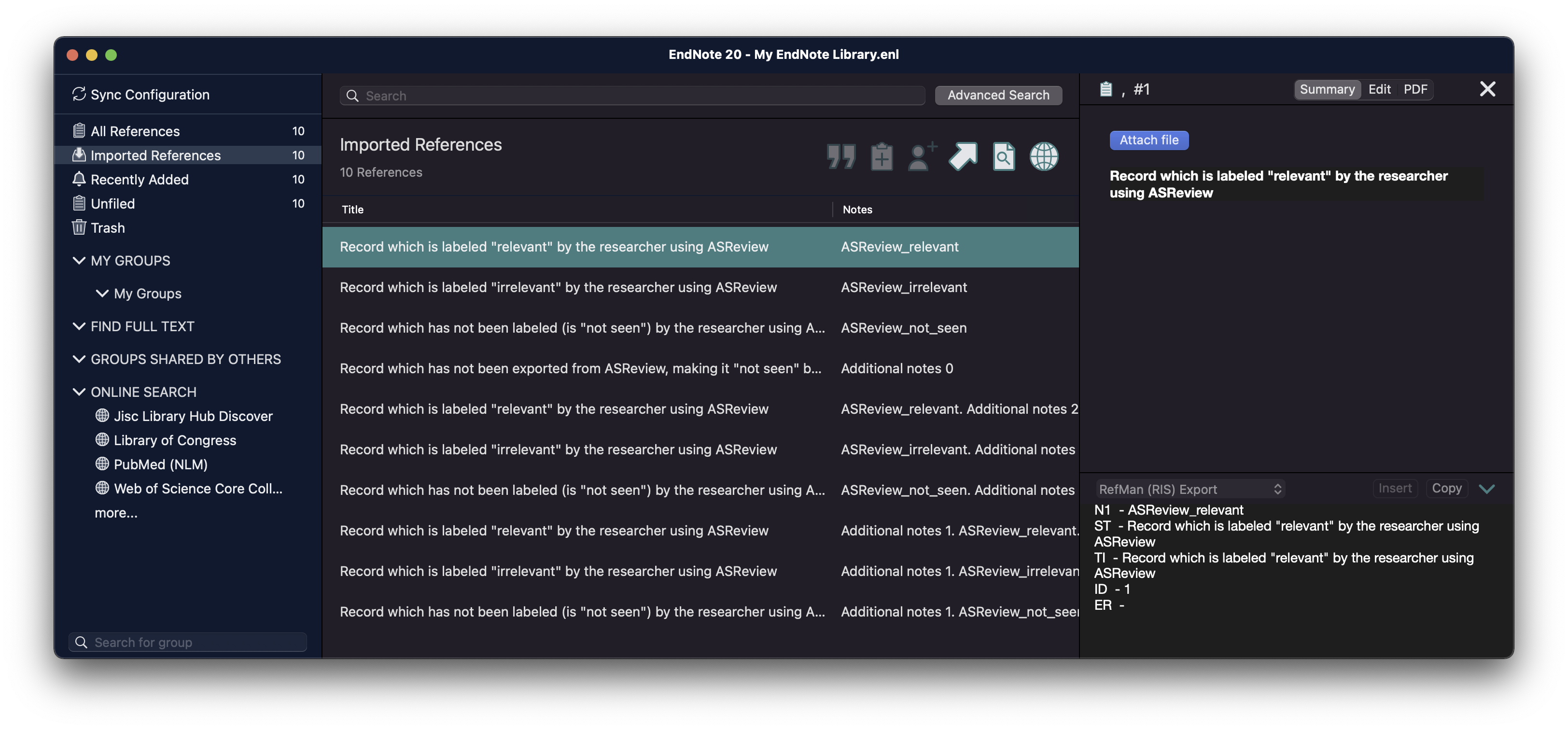
Example record with a labeling decision imported to Endnote